
Une blockchain de 3ème génération
Les technologies SEGMENT
Si les questions mathématiques, algorithmiques, cryptographiques ou méthodologiques sont complexes à aborder, les solutions apportées le sont tout autant.
Cette page aborde le coeur des technologies utilisées par SEGMENT mais sans toutefois entrer dans des codes et détails techniques difficilement accessibles aux non-professionnels. Elle vous propose un tableau global – certainement insuffisant pour les experts de ces questions – des approches développées dans SEGMENT.
La cryptographie dans SEGMENT
| Périmètre | Protocole / garantie |
|---|---|
| Privatisation des projets | Cubes 3D autonomes « permissioned » |
| Sécurisation des nœuds | Identifiants combinant CSPRNG et déterminisme algorithmique |
| Sécurisation des données | Sharding global de la chaîne |
| Sécurisation des tokens | Cryptographie anamorphique + Merkle Tree (hash) |
| Unicité des tokens | KYT pour tokens non fongibles (NFT) |
| Sécurisation des échanges | Chiffrement homomorphique + Vernam « One Time Pad » |
| Sécurisation langagière des échanges | Langages SALT/SLU (Synchronous Artificial Languages for Transactions) |
| Sécurisation des transactions | Analyse POI (Proof of Identity) |
| Sécurisation du consensus | Sélection aléatoire des approvers (DAG) |
| Sécurisation langagière du consensus | Langages SALT/SLU |
| Identification / authentification des utilisateurs | MFA + Captcha + Q/R + KYC optionnel |
Sécuriser. Garantir. Appliquer.
Technologies, cryptographies, protocoles
1. Langages
Javascript + Nodes

L’essentiel des opérations menées sur SEGMENT (transactions, stockages, contrôles, interactions) se passe au niveau de chaque machine connectée (UA : User Agent). Pour cette raison SEGMENT utilise massivement ES6 comme langage prioritaire + Node.js comme langage serveur (Gossip machines).
Les interactions concernant des objets IoT utilisent Go ou Python.
Les interfaces utilisateurs sont écrites en React.
→ Tous ces langages informatiques sont maîtrisés par tous les développeurs web ; ils ne nécessitent donc aucun apprentissage.
2. Machines
Statut des nodes
Les machines connectées à SEGMENT sont toutes par définition des UA full-Nodes, dotées de toutes les capacités et outils nécessaires pour mener les différentes opérations possibles, que ce soient des ordinateurs puissants, de simples phones ou des appareils IoT.
Chaque Node est individuellement identifié par une série complexe de chiffres présentant des milliers de millions de milliards de possibles distincts, empêchant ainsi l’usurpation d’identité (Sybil attack) par attaque brute force : voir plus bas, chapitre « Sécurité ».
SEGMENT permet la création de GOA (groupe d’objets associés) partageant un identifiant commun et un wallet commun, autorisant ainsi la création de DAO temporaires, organisations opportunistes en charge de réaliser certaines tâches.
Techniquement, un point x,y,z de chaque cube (voir ci-dessous, point 3) est affecté à l’hébergement des DAO ; aucune machine ne peut individuellement y être localisée. Chaque machine détient un certain nombre de parts dans la DAO (versement depuis son wallet au wallet DAO) et un smart-contract répartit les revenus selon des règles prédéfinies entre les acteurs de la DAO. Celle-ci est dissoute quand sa mission est terminée.
3. Les cubes 3D
Des projets applicatifs distincts
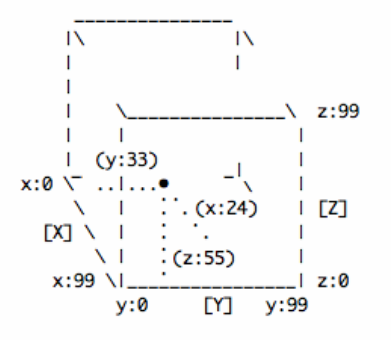
SEGMENT est architecturalement constitué de plusieurs milliers de cubes 3D virtuels étanches les uns aux autres. Chaque cube est un projet/client distinct, inaccessible par les machines qui n’y sont pas invitées (blockchains privées). Un cube particulier est public et ouvert à toute machine : c’est SEGMENT en version blockchain publique. L’ensemble de ces cubes architecturés font de SEGMENT une blockchain hybride.
Chaque cube 3D est constitué d’un million de points distincts (x: de 0 à 100, y: de 0 à 100, z: de 0 à 100), et chaque point x,y,z peut accueillir un million de machines différentes, individuellement identifiées de 000000 à 999999. Cette organisation spatiale en cubes+points permet donc d’intégrer 1000 milliards de machines sur chaque cube, soit plus de 120 machines par être humain vivant sur cette Terre… et SEGMENT contient des milliers de cubes.
Chaque cube/projet étant autonome des autres, il peut développer ses propres couches applicatives, fonctionnalités et protocoles spécifiques contruits via l’API distribuée en surcouches des applicatifs, fonctionnalités et protocoles de base qui forment le Core de SEGMENT.
4. Données
Les chaînes de blocs

Toute machine détient une partie (Sharding) de la blockchain globale, qui elle n’existe nulle part en version intégrale. Les informations sont détenues cryptées : le protocole cryptographique sera différent selon les machines, leurs caractéristiques, leurs ID, leurs positions dans le cube 3D, ce qui rend leur décryptage complexe à mener puisque sans connaître ces caractéristiques et critères spécifiques il n’est pas possible de rétro-ingéniérer l’encryptage initial.
Ce découpage de la chaîne globale en segments contraint les Nodes à dialoguer en permanence pour accéder aux datas dont elles ont besoin pour réaliser une opération quelle qu’elle soit.
Les chaines segmentées sont constituées de blocs empilés. Ces blocs sont de différents types : certains décrivent des wallets (propriétaire + horodatage + type de contenu + valeur contenue + hash de contrôle*), d’autres contiennent des portions de smart-contracts, d’autres encore des datas dynamiques ponctuelles décrivant le statut de la machine à un moment donné d’un process en cours la concernant : transaction, approbation, etc.
* Le hash de contrôle (Merkle Tree) permet de vérifier la signature des 5 Approbatrices ayant validé la transaction.
5. Objets
Les Tokens

SEGMENT est un outil global de gestion de tokens. Un token est un bien (physique ou numérique) qui peut être individuellement identifié et dont la représentation peut être numériquement stockée.
Les objets contenus dans les blocs-wallets peuvent être de différents types et de natures différentes. Chaque cube 3D/projet construit sur SEGMENT peut définir le type et la nature des tokens créés, détenus et échangés : monnaies fiat ou crypto, objets réels (par exemple type, n° de série, n° d’immatriculation d’un véhicule), objets numériques (référence stéganographiée dans une photo signée par son auteur), jetons de holder C.A (voir la page DAX dédiée : « Digital Assets Exchange » https://segment.pm/), capacités et droits (d’accès, de votes, de cessions d’actifs…), mais aussi positions géolocalisées, référence à un objet sur IPFS, etc.
SEGMENT fait la différence entre tokens fongibles et tokens non-fongibles (NFT). Si je vous emprunte 10 (CHF, euros, dollars) et que je vous rends un billet de 10 le lendemain, nous sommes quittes même si ce n’est pas le même billet que celui de la veille parce que les monnaies fiat sont « fongibles » : l’une équivaut exactement à l’autre. Elles sont indistinctement interchangeables. En revanche si je vous demande de me prêter votre Ferrari et que le lendemain je vous rends une Dacia nous allons vers un problème grave : les voitures sont des objets non-fongibles. L’une ne se confond pas avec l’autre.Si des tokens sont définis comme NFT, ils héritent d’identifiants spécifiques permettant de tracer leur production et leurs déplacements d’un compte à un autre : KYT (« Know Your Token ») est l’équivalent dans SEGMENT du KYC (« Know Your Customer ») bancaire : une identification individualisée. Un token sera NFT ou ne le sera pas, et ses conditions de transaction seront alors différentes. Cette différenciation « objet ≠ objet » est importante dans bien des cas (DeFi par exemple).
Quelle est l’essence du « token » ?
C’est une des conséquences directes de l’application de la blockchain à de multiples secteurs en dehors de la finance. A chaque nouveau cas d’usage en cours de test à la surface de la terre, on fabrique un token qui est une unité de compte, un quantum d’information en fait, que l’on certifie et authentifie avec la blockchain. C’est cette action de fabrication d’une unité d’oeuvre particulière que l’on appelle tokenisation. De quelque chose de continu ou de masse, on a extrait des unités que l’on peut commercialiser, échanger, valoriser, stocker si c’est possible, transporter, partager…
Par exemple pour le temps donné aux autres à un niveau local : authentifié, certifié et d’une certaine manière valorisé aux yeux de tous de par la transparence apportée par la blockchain. L’heure de bénévolat (crypto-heure ? ou crypto-bienveillance ? : ) devient un token qui peut lui même être échangé contre un token d’énergie. Avec un avantage : transparence, visibilité, effet d’entrainement et d’émulation … et action démultipliée à longue distance comme nous le verrons plus loin.
Pierre Paperon : « La tokenisation du monde est en cours » (LinkedIn).
6. Cryptographie
Cryptographie anamorphique

Déformation anamorphique : seul l’utilisateur placé au bon endroit est capable de restituer l’image originale
Imaginez un appareil magique vous permettant de parler à haute voix au milieu d’une foule compacte et n’être compris que par les personnes à qui vous destinez votre message : c’est la meilleure définition qu’on puisse faire de la cryptographie anamorphique, une création SEGMENT destinée à anticiper les futures attaques quantiques.
Chaque machine (ou groupe de machine) étant positionnée en x,y,z dans son cube 3D virtuel, l’émetteur et le(s) récepteur(s) sont distants d’une certaine valeur angulaire dans les trois directions x,y et z : DAE = distance, azimuth et élévation. Un simple calcul trigonométrique permet de mesurer cette distance et l’orientation de la droite reliant émetteur et récepteur(s). En partant du point x,y,z de l’émetteur, il n’existe donc qu’un seul point validant des valeurs prédéfinies d’angle et de distance.
La cryptographie anamorphique consiste simplement à écrire un message posté publiquement dans le Gossip (dial public machines) encrypté de telle façon que seule la machine (ou les machines) du point x,y,z de destination puissent le comprendre… et donc l’utiliser. Quand Alice souhaite passer un message à Bob, elle va donc produire un message encrypté selon ces valeurs strictement spécifiques à Bob+Alice.
Un peu d’explications. Lors de l’inscription d’une machine Alice, un point du cube 3D lui est algorithmiquement affecté, par exemple x:21 y:52 z:44 ; cette valeur 215244 est écrite dans son identifiant stocké encrypté dans ses datas. Comme vu plus haut, Alice hérite également d’un numéro aléatoirisé à 6 chiffres, par exemple 034982. Pareil pour la machine Bob qui vaut par exemple 458902 en position x,y,z et 800241 en numéro randomisé.
Il se trouve qu’une troisième machine, Chris, est par hasard sur le même x,y,z que Bob mais de numéro 378125… Si Alice encrypte son message selon la permutation 215244 → 458902 + 000000, Bob et Chris comprendront son message puisque toutes deux sont sur le même point du cube. Mais si Alice l’encrypte selon une autre permutation : 215244 → 458902 + 800241 alors seul Bob pourra le décrypter.
Un mot sur ces « permutations » qui permettent à la cryptographie anamorphique de sécuriser les dials Node-to-Node : chaque valeur x,y,z (position de la machine dans son cube 3D) présente un million de variantes, allant de 000000 à 999999. En partant de 62 signes clavier A-Z, a-z- et 0-9 (pour simplifier… SEGMENT en comporte beaucoup plus) il existe 62! permutations possibles, soit environ 3.146997326e85 (=85 zéros derrière, donc un paquet de milliards de milliards de milliards).
Chacune de ces permutations peut être numérotée et produite individuellement. On peut ainsi trouver la permutation exacte de Bob, qui serait la 458902ème si l’on ne tenait compte que de sa position x,y,z. Ça donnerait par exemple la table e4B8cmGPu2 ... Zk1bS (nos 62 signes permutés). En réalité dans SEGMENT c’est beaucoup plus compliqué puisqu’il y a plusieurs centaines de signes utilisables et que les permutations pour chaque machine tiennent compte non seulement de sa position et de son numéro, mais aussi du nom de son propriétaire encodé sur 6 chiffres lui aussi, des caractéristiques de la machine (Fingerprint sur l’OS, ses capacités processeurs, etc) ou encore du timestamp de son inscription.
Transposition dynamique
Le chiffrement de caractères individuels (Stream Cipher) permet au chiffrement de commencer immédiatement, évitant ainsi d’avoir à accumuler un bloc complet de données avant le chiffrement, comme cela est nécessaire dans un chiffrement par bloc conventionnel.
L’un des objectifs de la transposition dynamique est d’exploiter le concept de « secret parfait » de Shannon. Ceci se produit lorsque l’opération de chiffrement peut produire toutes les transformations possibles entre le texte en clair et le texte chiffré. Par conséquent, même la force brute ne fonctionne plus, car le fait de passer en revue toutes les clés possibles ne fait que produire toutes les valeurs possibles.
Un aspect intéressant de la transposition dynamique est le masquage fondamental de chaque opération de chiffrement particulière. Il est clair que chaque signe est chiffré par une permutation particulière. Si l’adversaire savait quelle permutation s’est produite, ce serait une information très utile. Mais l’adversaire ne dispose que du texte chiffré pour exposer la permutation de chiffrement, et une vaste pléthore de permutations différentes prennent chacune exactement le même texte en clair pour le même texte chiffré. En conséquence, même une attaque de texte en clair connu n’expose pas la permutation de chiffrement. Il en résulte un chiffrement dont la puissance est inhabituelle.
Terry Ritter : « Ritter’s Crypto Bookshop »Revenons aux permutations : chaque machine a donc sa table en propre et qui n’appartient qu’à elle.
Si sur 10 signes azertyuiop (pour simplifier à l’extrême) la table permutée de Bob est rypzoeitua et celle d’Alice est oeypatuezir, Alice voulant envoyer le code azerty à Bob lui enverra le message public ouyaep (son « a » vaut « o », son « z » vaut « u », etc.) qu’il comprendra comme signifiant azerty. Chris qui possède la table urapituyez verra bien passer le message d’Alice puisqu’il est public, mais comprendra utairp… ce qui ne veut rien dire.
Dans une utilisation réelle de SEGMENT, si le message azerty signifie « fais ceci » comme condition contractuelle, seule la machine Bob le comprendra et exécutera l’opération requise. La cryptographie anamorphique est bien évidemment beaucoup plus complexe que cela mais nous aborderons cette question dans un autre chapitre : celui des langues de transactions.
Cryptographie homomorphique

La quasi-totalité des blockchains (sauf SEGMENT, évidemment…) utilisent des systèmes cryptographiques à doubles clés, privées et publiques. C’est l’application directe de la fameuse Loi de Kerschoffs qui dit que « la sécurité d’un système d’information ne peut résider que dans l’existence d’une clé tenue secrète ». Ces systèmes à clés sont actuellement basés sur une factorisation complexe de nombres premiers s’appuyant sur des fonctions mathématiques de courbes elliptiques (ECDSA) permettant de produire une clé publique à partir d’une clé privée.
Ce système à doubles clés a de nombreux avantages mais aussi quelques inconvénients :
• Perdre sa clé privée c’est perdre tout, et se la faire voler c’est tout se faire voler. D’où l’obligation absolue de la protéger, certains n’hésitant pas à la placer dans un coffre en banque.
• Rien ne garantit que le hash produit ne subisse pas de collisions possibles, c’est-à-dire où 2 valeurs différentes produisent un hash identique. Cette collision a été expérimentée et documentée il y deux ans sur des protocoles de hashage SHA-1 dans un laboratoire de recherche où des ordinateurs connectés ont produit cette collision en quelques semaines d’attaque en brute force. Les blockchains utilisent des protocoles SHA-256 impossibles à collisionner à l’heure actuelle, mais l’arrivée probablement assez rapide (10 à 20 ans) d’ordinateurs quantiques fait peser de sérieuses menaces sur SHA.
• Mais il y a pire : il est aujourd’hui considéré comme absolument certain par tous les experts que les courbes ECDSA ne résisteront pas aux attaques quantiques puisque la factorisation de nombres premiers extrêmement élevés (1024 bits) sera opérable en quelques minutes, et donc que partant de n’importe quelle clé publique on pourra aisément retrouver la clé privée à partir de laquelle elle a été générée. Ce qui, en gros, revient à dire que tous nos petits secrets seront étalés sur la place publique.
C’est pourquoi depuis le début de sa conception SEGMENT s’est détourné de ces protocoles cryptographiques pour inventer les siens, notamment la cryptographie anamorphique. Mais à elle seule celle-ci ne suffit pas : elle forme certes l’ossature cryptographique des échanges, mais si l’exploration méthodique valeur par valeur de ses tables de permutations est aujourd’hui techniquement impossible (des milliards de milliards de milliards de possibles… très exactement 821657867364790503552363213932185062295135977687173263294742533244359449963403342920304284011984623904177212138919638830257642790242637105061926624952829931113462857270763317237396988943922445621451664240254033291864131227428294853277524242407573903240321257405579568660226031904170324062351700858796178922222789623703897374720000000000000000000000000000000000000000000000000…), elle ne le sera peut-être plus dans 15 ou 20 ans.
C’est pourquoi à l’anamorphique se surajoute l’homomorphique. La cryptographie homomorphique consiste simplement (tout est relatif) à confier à un Node ou à plusieurs d’entre eux le calcul algorithmique d’un résultat à partir de données encryptées et à retourner ce résultat sans avoir à décrypter ces données. En d’autres termes, le résultat de sortie sera strictement le même que celui produit en opérant le même calcul avec les données initiales non-cryptées. Ce sont des fonctions algorithmiques intéressantes parce qu’elles relèvent de ce qu’on appelle en cryptographie les « protocoles ZKP » : « Zero-Knowledge Proof« , ou « Preuve à divulgation nulle » (PDN) en français.
Supposons que vous soyez en possession d’une information très secrète que seuls vous et moi connaissons… Nous sommes en public et je dois m’assurer que vous êtes bien la personne que je recherche : si je vous demande de me chuchoter le secret à voix basse, quelqu’un avec un micro très puissant pourra l’entendre, quelqu’un sachant lire sur les lèvres pareillement, si je vous demande de me l’écrire sur un papier quelqu’un équipé d’un télescope depuis un toit voisin pourra le lire, quelqu’un pourra me l’arracher des mains, bref, le secret n’en est plus un.Accessoirement, en cryptographie on appelle ça des « attaques par canaux auxiliaires » : des chercheurs en sécurité ont démontré qu’une clé privée RSA entrée au clavier pouvait être retrouvée en « écoutant » le travail et le cadencement des opérations d’un microprocesseur. On a même pu reconstituer une conversation tenue entre deux personnes dans une pièce fermée par l’observation des infimes vibrations du verre d’une simple ampoule au plafond… Autant dire que les attaques par canaux auxiliaires sont des choses à prendre très au sérieux.Et donc pour être sûr que vous êtes la bonne personne, je vais vous demander non pas de me dire le secret, mais de me prouver que vous le détenez sans jamais avoir à le divulguer : PDN = « Preuve à divulgation nulle ». Par exemple si l’on parle d’une personne précise je vous demanderai sa date de naissance. Même si un hacker nous écoute, les chances pour qu’il retrouve de qui l’on parle parmi les 300 000 personnes nées le même jour dans le monde peut lui prendre un certain temps. Sauf que pour SEGMENT ce ne sont pas 300 000 variantes possibles qui entrent en jeu, mais des milliards de milliards de milliards.
Les ZKP homomorphiques sont utilisés dans SEGMENT pour évaluer les POI (Preuves d’Identité) garantissant que chaque machine* est bien qui elle prétend être. Toute machine frauduleuse (attaque Sybil ou autre) est immédiatement détectée par les autres (échec POI) et ses datas réinitialisées à zéro : un hacker détenteur d’un wallet avec toute sa fortune en cryptomonnaie dedans perdra tout, avec impossibilité de reconstituer ses datas deletées. Il pourra bien sûr sauvegarder ces données et les reconstituer artificiellement sur sa machine d’attaque, mais son souci sera que plus aucune machine du réseau ne le reconnaîtra puisque toute référence à sa machine aura été supprimée sur toutes les machines en contenant dans leurs Shards. Il ne lui restera plus qu’à tenter une attaque des 80% (voir plus bas) mais c’est une autre histoire.
*Cryptographie de machines
Plutôt que de se limiter aux opérations arithmétiques, la « cryptographie de machines » tend à utiliser une grande variété de composants techniques et matériels qui peuvent ne pas avoir de descriptions mathématiques concises. Plutôt que de simplement mettre en oeuvre un système d’expressions mathématiques, la complexité est construite à partir des divers composants disponibles pour le calcul numérique.
Terry Ritter : « Ritter’s Crypto Bookshop »SEGMENT homomorphe ses échanges-machines ayant besoin de l’être via une déclinaison de l’algorithme NewHope (Homomorph Lattice-based Cryptography Quantum-Resistant Ring-LWE).
Cryptographie "One Time Pad" (masque jetable)

Il est connu et démontré depuis près d’un siècle que la sécurité cryptographique idéale existe : c’est le « masque jetable », ou protocole de Vernam.
On prend un message, on permute chaque signe selon une grille à usage unique (elle ne doit JAMAIS resservir) et on l’envoie. Son destinataire, détenteur de cette grille, sera de ce fait le seul à pouvoir le décrypter et à le comprendre.
Le « téléphone rouge » qui relie les dirigeants de ce monde utilise un Vernam en version « audio » pour sécuriser leurs échanges.Le seul problème depuis près d’un siècle – et il a été longtemps insoluble – est qu’on ne savait pas comment transmettre cette grille unique au destinataire du message en étant certain que personne ne puisse s’en emparer au passage…
• si je lui envoie dans le message ce n’est plus une grille secrète,
• si je lui envoie avant, rien ne garantit qu’elle n’aura pas été interceptée,
• si je lui passe par mail ou par SMS rien ne dit que son mail ou son phone ne sont pas écoutés,
• si je lui passe selon un code convenu entre nous rien ne m’assure qu’une attaque MIM (« Man-in-the-Middle« ) n’en n’a pas pris connaissance, etc.
Et si je réutilise ne serait-ce que deux fois la même grille, rien ne me dit que le premier message n’a pas été stocké par un attaquant attendant la suite, et que comparant le premier et le second message il ne parviendra pas à relever des occurences, des similitudes, des fréquences redondantes et par attaque en force brute reconstituer l’un et l’autre… C’est exactement ce qui s’est passé en 1943 avec Enigma, la machine à coder de l’armée allemande, craquée par Alan Turing, génie mathématique et cryptographe qui, pour l’occasion, a inventé le premier ordinateur au monde.
Le « secret parfait » exige d’un système qu’après l’interception d’un cryptogramme par l’ennemi, les probabilités a posteriori que ce cryptogramme représente divers messages soient exactement identiques aux probabilités a priori du même message avant l’interception. Le secret parfait est possible mais nécessite, si le nombre de messages est fini, le même nombre de clés possibles.
Claude Shannon : « Le secret parfait »Grâce aux travaux de cryptographes talentueux, une solution est apparue ces dernières années : le « Secret Sharing » (partage secret). Dans SEGMENT nous utilisons principalement une version adaptée de l’algorithme de Blakley (SSB) et plus rarement celui de Shamir (SSS)
CSPRNG

Derrière l’acronyme CSPRNG « Crypto-Secured Pseudo-Random Number Generator » se cache un ensemble algorithmique en charge de produire des nombres aléatoires sans possibilité d’échafauder des algorithmes de simulation capables de produire des fréquences de sorties non-équiprobables.
Les fonctions informatiques classiques de production de nombres aléatoires de type Math.random() génèrent sur le long terme des occurrences prédictibles dans leurs ordres d’apparitions.
Une séquence de chiffres est considérée comme « 100% aléatoire » si elle est :
• équiprobable : il y a pour chaque chiffre la même chance d’obtenir n’importe quel signe de la séquence,
• uniformément distribuée : la probabilité est la même dans le temps pour chaque tirage,
• statitiquement indépendante : il n’y a aucun lien de causalité entre un groupe donné de chiffres et n’importe quel autre groupe pris au hasard,
• non prédictible : il est impossible pour une entrée donnée d’en prédire la sortie,
• non reproductible : il est impossible d’obtenir volontairement le même résultat quel que soit le nombre d’essais.
Les CSPRNG SEGMENT sont construits sur des entropies de Shannon imprédictibles à sorties équiprobables.
Une séquence de bits peut être appelée « idéalement aléatoire » si chaque nouveau bit ne peut être prédit de façon cohérente avec une réussite de 50% par toute technique possible, connaissant tous les bits précédents.
L’aléatoire est un attribut du processus qui génère ou sélectionne des nombres « aléatoires » plutôt que les nombres eux-mêmes. Mais les nombres portent la trace de leur création : si les valeurs sont réellement générées aléatoirement avec la même probabilité, on s’attend à trouver presque le même nombre d’occurrences de chaque valeur ou de chaque séquence de même longueur. Sur de nombreuses valeurs et de nombreuses séquences, nous nous attendons à voir des résultats se former dans des distributions qui correspondent à notre compréhension des processus aléatoires. L’aléatoire peut produire n’importe quelle relation entre des valeurs – y compris des corrélations apparentes (ou leur absence) – qui ne représentent jamais la production systémique du générateur utilisé.
Un générateur de nombres aléatoires idéal opère des sélections répétées parmi toutes les valeurs possibles. Idéalement, chaque valeur a la même probabilité d’être sélectionnée, et chaque sélection est effectuée indépendamment de toutes les autres sélections (Random Sampling). De cette façon, toute séquence possible peut être créée. Bien que certains schémas apparents puissent se produire par hasard, un CSPRNG idéal ne produit aucun schéma prévisible.
Terry Ritter : « Ritter’s Crypto Bookshop »
En complément

SEGMENT utilise parallèlement plusieurs autres protocoles cryptographiques pour sécuriser ses échanges et ses datas, par exemple :
• le protocole ISO 13616 mod97 (celui des IBAN bancaires, des CB, des numéros de Sécurité sociale…),
• la conversion de datas complexes BYTES [0,1]→TRYTES [-1,0,1] soit pour réduire leur poids, soit pour masquer leur valeur, soit pour vérifier que le résultat d’un calcul est conforme,
• décimales de π : une valeur est remplacée par sa première occurence dans les décimales de PI, par exemple la valeur « 999 » est en 1752ème position… le code 1752 une fois anamorphosé en ü_4ç pour Bob vaudra donc en réalité 999 pour lui,
• un hashage par protocole à clé (Siphash), considéré plus sûr que SHA, MD5, TEA ou AES : un hash est produit en partant d’une key de cryptage partagée homomorphiquement ou anamorphiquement,
• Salt & Pepper : une data est dotée d’un nombre indéterminable de signes complémentaires inutiles empêchant de la retrouver en comparant sa longueur avec des datas supposées similaires. « Salter » consiste à ajouter des signes spécifiques à une data spécifique, et « pepperiser » consiste à déterminer un nombre de signes aléatoires à surajouter à toutes les datas quelles qu’elles soient (scope global),
• Code d’authentification de message (MAC) : les messages de machine à machine sont signés par un code garantissant qu’il n’a été ni altéré ni modifié en route par un intercepteur (attaque MIM : Man-in-the-Middle),
7. Protocoles
Les transactions et leur langages

Pour SEGMENT toute requête est une transaction, qu’elle porte sur un échange de valeurs (Alice verse 100 unités de compte à Bob), sur une identification/authentification d’ID machine ou sur la communication de position géolocalisée d’un drone de livraison arrivé à destination.
Lorsqu’une transaction est lancée par une machine sur le gossip (dial public) elle l’est toujours sous forme cryptée anamorphiquement : seuls ses destinataires peuvent comprendre quoi en faire. Ce que le message contient sera lui aussi encrypté (voir les méthodes ci-dessus) préalablement son anamorphisation. Il existe donc un risque non-négligeable de collision : par exemple le message B_4û(Cn22kT posté par Alice à destination de Bob pourra signifier « Fais ceci » pour lui, mais aussi par un mauvais hasard « Voici mon code secret d’identification » pour une machine Chris à l’écoute du Gossip public. Ce qui peut poser problème.
Pour y pallier, SEGMENT utilise entre autres techniques un système de marquage (« flag ») des messages : si par exemple le message une fois anamorphiquement décrypté par son destinataire commence par « /@ » et se termine par « */ » alors il lui est vraiment destiné. Toute autre interprétation (par exemple « Ub » et « 4_ » comme flags encadrants) n’a aucun sens pour aucune autre machine.
Une transaction complète s’effectue en plusieurs étapes :
1. Alice dit « je suis Alice » en l’anamorphosant pseudo-aléatoirement selon des règles algorithmiques strictes : un point x,y,z de son cube 3D doit être désigné comme PTR (point de transaction).
2. si cinq machines au moins (nombre paramétrable selon les cubes/projets : plus il y a de machines à trouver plus la sécurité de la transaction sera assurée mais plus elle sera longue…) sont présentes sur ce point on passe à l’étape 3. Sinon, si on ne trouve que 1 à 4 machines, celles-ci déportent le PTR par DAG acyclique aux points x±i y±1 z±1. Il ne peut y avoir 0 machine sur le PTR : lors de leur inscription, les machines sont algorithmiquement (et non-aléatoirement) dotées d’une pos x,y,x. Le PTR est garanti par ce protocole.
3. une fois que les 5 machines approbatrices de la transaction sont sélectionnées (si il y en a 10 ou 100 ou 1000 sur le PTR le protocole en choisit 5 au hasard), celles-ci déterminent aléatoirement (par CSPRNG) une LTR, une langue de transaction. Il s’agit d’une version particulière d’anamorphisme où certaines tables de permutation sur un certain nombre de signes sont construites de façon à ce que ni ces tables, ni certains de ces signes ne soient partagés par les autres machines non-concernées par la transaction en cours.Comme toutes les langues du monde, cette langue LTR est dotée d’une syntaxe, d’un vocabulaire et d’une grammaire. Comme il existe des millions de millions de LTR possibles et que sa durée de vie sera celle de la transaction complète (3 à 5 secondes), aucune attaque n’est à craindre sur cette LTR le temps de son utilisation.
Cette LTR utilise certains signes comme verbes (grammaire), d’autres comme syntaxe, d’autres encore comme concepts (vocabulaire). Par exemple, la phrase ÄÖÌ[ÈW`ûôèì+&W?+ò/ passée dans le Gossip public par les 5 approbatrices signifiera S[W?U=Alice&$=1&h), ce qui, structurellement, demandera Send{ Wallet[user=Alice]+[token=euros] + horodatage } à d’autres machines du réseau (voir ci-dessous point 5 : « machines parentes »).4. Une fois la LTR créée les approbatrices demanderont à Alice de confirmer son ID (POI). Une fois celle-ci acquise et valide, elles lui demanderont ce qu’elle veut faire : « verser 100 unités à Bob ».
5. Les approbatrices demandent alors à certaines machines du réseau (tri sélectif par affinités « familiales » entre machines : ses frères, ses cousins… c’est inscrit dans l’ID/ADN de chaque machine) de leur retourner la demande précédente : « quelle est est la valeur actuelle du wallet d’Alice en euros ? ».
6. Les « parents » d’Alice renvoient cette valeur qu’ils partent chercher décryptée dans leurs blocs shardés et la retournent cryptée en LTR aux approbatrices. Si tous les retours (disons 20 ou 30) disent la même chose (« Alice possédait 1500 euros tel jour à telle heure/minute/seconde ») le consensus est immédiat : la transaction est acceptée : Alice est bien Alice et elle détient en euros de quoi en verser 100 à Bob… Les approbatrices demandent alors aux « parents » d’Alice présents sur le réseau d’actualiser son wallet (nouvel horodatage + valeur = 1400) et aux « parents » de Bob de faire de même : nouvel horodatage et valeur + 100.
7. Si les réponses sont discordantes on entre dans un cycle appelé en cryptographie blockchain « le Dilemme des Généraux Byzantins » (voir plus bas : 9. BFT) : face à des ordres contradictoires, comment prendre la bonne décision ? En l’occurence chaque approbatrice prend connaissance des 20 ou 30 réponses et affecte à chaque réponse un % de fiabilité ; en additionnant les 5 pourcentages (le sien et les 4 autres) et en comparant chaque % produit par les autres au sien, chaque approbatrice détermine si elle est d’accord ou pas. Si a minima 4 machines sur les 5 sont d’accord, chacune avec plus de 90% de fiabilité, le consensus est réalisé et la transaction acceptée (voir point 6 ci-dessus pour la suite : actualisations de blocs).
8. Si plus de 80% des réponses « parents » sont identiques (même horodatage et même valeur) et que 20% diffèrent (horodatage plus ancien et autre valeur), on considère que ces 20% sont des parents non-actualisés : on n’en tient pas compte. Ils seront mis à jour sitôt la transaction achevée.
Si parmi toutes les réponses l’une propose un horodatage très récent et une valeur anormalement élevée (toutes disent que Alice détient 1500 euros mais 1 seule la crédite de 15 millions d’euros…) on considère que cette machine est frauduleuse et elle est instantanément réinitialisée.
Ces protocoles de transaction tels qu’exposés ici sont relativement simplifiés pour en faciliter l’approche et la compréhension générale. Dans la réalité de SEGMENT ils sont beaucoup plus complexes et nécessiteraient une documentation technique complète.
8. Sécurité
Data et transactions
Aucune donnée n’étant stockée sur aucun serveur, leur sécurisation n’est pas « physique » au sens où il faudrait à la fois se préoccuper de la sauvegarde régulière des bases de données sur des serveurs de backup, de leur protection contre des attaques malveillantes et contre l’infrastructure hardware elle-même. Il appartient en revanche à chaque détenteur d’appareil (Node User-Agent) de veiller à leur sécurisation contre la perte ou leur vol, comme il le ferait de sa CB ou de sa clé privée. On y reviendra au chapitre suivant.
Par construction, personne – ni fournisseur d’accès, ni fabricant d’appareil ou de composants, ni développeur d’applicatif – ne peut accéder aux données de base ayant permis la création de l’ID de la machine (position, numéro, fingerprint, timestamp, etc.) ; dès lors tenter de les reconstituer devient tâche ardue : pour chacune de ces valeurs il existe 3644153415887633116359073848179365185734400 variantes ; trouver la bonne par brute force prendrait 2.7577419697518847e21 siècles (avec 21 zéros derrière) à raison d’un test/seconde.
A cette exception près, tous les algorithmes de SEGMENT sont de type ADP :
• Auditables : ils peuvent être consultés et auscultés.
• Déterministes : à entrée égale ils produiront une sortie égale, toujours la même.
• Prédictifs : à entrée donnée ils produisent une sortie anticipable sans avoir nécessairement besoin d’être exécutés.

Les attaques possibles sur des transactions en cours sont multiples et toutes appellent des réponses particulières :
• on peut exclure de suite la découverte fortuite de la table LTR dans les 3 à 4 secondes que dure une transaction ; une fois celle-ci terminée, la LTR dynamique ne sert plus à rien.
• une machine peut tenter de se faire passer pour une autre (Sybil attack). Il suffit à l’attaquant d’accéder aux données présentes sur une autre machine dont il parviendrait à prendre le contrôle pour remplacer ses datas par celles de la machine piratée. Les IDs sont ainsi conçues – notamment à travers le Fingerprint – que reconstituer toutes les datas nécessaires pour en tirer exactement la même série de chiffres au final est mission quasi-impossible puisque quoi qu’il fasse, les deux machines ne seront jamais exactement les mêmes… Une seule micro-variante produira des résultats différents, et résultats différents = réinitialisation automatique de la machine.
• autre option évoquée plus haut : l’attaquant stocke ses datas actuelles à part, en tente de nouvelles puis enfin réinstalle les siennes après différents échecs à être reconnu (consensus sur POI echoué). Problème : plus aucune machine ne reconnaîtra la sienne après sa réinitialisation.
• dernière option : l’attaque massive pour prendre le contrôle du système en créant autant de machines que nécessaire, réelles ou virtuelles. Nouveau problème pour notre hacker : ne sachant combien de machines sont connectées sur chaque point du cube, il devra en créer plus de 80% pour être à peu près sûr d’en avoir une majorité écrasante sur chaque point, de façon à être certain qu’au moins 4 des siennes seront aléatoirement appelées pour devenir approbatrices de transactions qu’il souhaite détourner en sa faveur. Un million de points fois disons 100 machines sur chaque point = 100 millions de machines à créer.
• problème suivant : il est statistiquement parlant peu probable que toutes soient aléatoirement équitablement réparties dans le cube 3D : il peut donc se retrouver avec 1000 machines sur un point et strictement aucune sur les points adjacents ; les chances de posséder 4 machines sur 5 (80% comme seuil de certitude d’être appelé à transacter) nécessiterait d’au moins doubler le nombre de machines d’attaque : de 100 millions on passe à 2 ou 300 millions. Pas simple à réaliser, ni en temps ni en énergie ni en argent. Si les blockchains classiques garantissent qu’en détenir 51% suffit pour invalider un bloc de transaction licite pour forcer la validation d’un bloc forké illicite, dans SEGMENT ce type d’attaque n’est pas possible.
• les attaques par double dépense (un attaquant lance deux transactions simultanées pour un montant total excédant ses actifs) ne sont pas non plus possibles dans SEGMENT : quand Alice lance une transaction son statut passe instantanément de 1 à 0. Il reviendra à 1 (capacité à lancer une nouvelle transaction) quelques secondes plus tard, quand le cycle de sa première transaction sera achevé.
• un attaquant sauvegarde les dials en cours sur sa propre machine et, à force, parvient à repérer suffisamment de constantes pour déterminer qui parle à qui et ce qui se dit. SEGMENT produisant plusieurs millions de LTR (langue de transactions de type SALT/ULS : Synchronous Artificial Languages for Transactions sur unités lexicales sémantiques) il est impossible de repérer des fréquences d’occurrences redondantes sur des séquences très courtes : un message moyen ne comprend qu’une vingtaine de signes.
• s’il mène une attaque en force brute pour tester toutes les langues possibles par permutations de signes, le résultat obtenu étant lui-même un cryptage (pas de langage humain échangé puisque SEGMENT n’est qu’une « micro-société de machines ») il y a indécidabilité sur le « vrai » résultat : partir de B4)n8i et obtenir des milliers de résultats [ 5Fv-hL, P4dcàI, …, 67gyPz ] ne dit pas quel est le vrai utilisable.
• s’il tente de poster manuellement et intentionnellement des séries de faux messages cryptés pour en évaluer les résultats en retour (et ainsi parvenir à prendre le contrôle du Gossip), au pire il ne se passe rien (aucune machine ne comprend), au mieux le « vrai » retour reste indécidable.
• s’il tente de retrouver sa parenté pour contraindre tous ses « frères/cousins » à sur-évaluer le contenu de ses wallets pour des transactions falsifiées, non seulement la mise à jour de leurs blocs ne peut être effectuée que sur instruction de 5 machines approbatrices de même position x,y,z mais en plus le hash de contrôle de chaque wallet ne sera plus cohérent avec ses contenus.
… ce ne sont là que quelques exemples, nous avons recensé plus de 30 types d’attaques PUV (Points uniques de vulnérabilité) différentes possibles sur SEGMENT et toutes ont leur réponse.
9. Résilience
Tolérance aux pannes byzantines
La tolérance aux pannes byzantines est la propriété d’un système capable de résister à la classe de pannes dérivée du problème des généraux byzantins. Cela signifie qu’un système BFT peut continuer à fonctionner même si certains des nœuds échouent ou agissent de manière malveillante.
Le « problème des généraux byzantins » suppose que chaque général a sa propre armée et que chaque groupe est situé à différents endroits autour de la ville qu’il a l’intention d’attaquer. Les généraux doivent s’entendre sur l’attaque ou la retraite. Peu importe qu’ils attaquent ou battent en retraite, tant que tous les généraux parviennent à un consensus, c’est-à-dire s’accordent sur une décision commune afin de l’exécuter en coordination.
Chaque général doit décider: attaque ou retraite (oui ou non). Une fois la décision prise, elle ne peut pas être modifiée et tous les généraux doivent s’entendre sur la même décision et l’exécuter de manière synchronisée. Un général ne peut communiquer avec un autre que par des messages, qui sont acheminés par un courrier : le défi du problème des généraux byzantins est que les messages peuvent être retardés, détruits ou perdus. De plus, un ou plusieurs généraux peuvent choisir (pour quelque raison que ce soit) d’agir de manière malveillante et d’envoyer un message frauduleux pour tromper les autres généraux, conduisant à l’échec de l’attaque.Si nous appliquons le dilemme au contexte des blockchains, chaque général représente un nœud de réseau et les nœuds doivent parvenir à un consensus sur l’état actuel du système. En d’autres termes, la majorité des participants au sein d’un réseau distribué doit accepter et exécuter la même action afin d’éviter un échec complet.
Par son protocole de consensus pré-bloc à >= 80% d’approbation SEGMENT est 100% BFT : un ou plusieurs nodes peuvent mentir et tricher sans altérer le résultat final.
10. Utilisateurs
Contrôles et KYC

Dans un système classique de gestion des interactions entre utilisateur et service on utilise le schéma [ User+UA ]→Service : User utilise son UA (sa machine) pour se connecter au service, que ce soit par l’entrée d’un couple login+password, ou par l’entrée d’un code secret, ou par l’entrée de quoi que soit d’autre permettant l’authentification de User.
Dans SEGMENT l’interaction User/Service est conçue différemment : elle applique le schéma User→[UA+Service]. Les UAs sont connectés à SEGMENT en tant qu’acteurs (Nodes) – ce sont eux qui dialoguent, transactent, interagissent, prennent des décisions – sans que User ait à intervenir. Reste à connecter celui-ci à sa machine et à l’authentifier.
La question est donc : lorsqu’une machine « UA as Node » lance une transaction sur le réseau (Gossip), comment être sûr de User ? …en d’autres termes : comment créer de la confiance sans tiers extérieur garantissant la véracité/fiabilité d’une information ? C’est la raison d’être des technologies blockchain.
Concrètement, comment être certain que quand un phone lance une transaction « Alice verse 100 à Bob » le phone d’Alice est bien entre les mains d’Alice et pas dans celles de Bob… ou de n’importe qui d’autre.
Un certain nombre de dispositifs de contrôles/sécurité sont implémentés dans SEGMENT :
• Quand User s’inscrit (ou plutôt inscrit sa machine) il doit se poser à lui-même 3 questions et donner les 3 réponses. Il veillera à poser des questions auxquelles lui seul peut avoir la réponse… une question standard de type « où suis-je né ? » ou « comment s’appelait mon premier chat ? » peut permettre à un attaquant (surtout un proche… ça arrive) de trouver la réponse en quelques minutes. En revanche, la réponse précise et correcte à la question « où ai-je mangé mon premier Big Mac ? » est plus compliquée à trouver du premier coup. Quand User lance une transaction on lui présente une liste de 20 questions dont au moins une des siennes, les autres sont tirées au hasard ; il doit retrouver sa(ses) question(s) et y répondre sans erreur possible. Un script de type Levenshtein/Jaro-Winkler analyse sa réponse et détermine si les erreurs de frappe (une minuscule au lieu d’une majuscule par exemple) sont invalidantes ou pas.
• Les données à entrer par User au clavier s’effectuent sur un clavier virtuel à taille/position aléatoire à l’écran : des attaques par Keysnuffing (capturer les signes entrés au clavier physique) ou par détection de l’endroit où l’écran a été cliqué deviennent impossibles.
• Un CAPTCHA basé la table des permutations propre à la machine présente une série de 8 caractères successifs à reproduire, garantissant que User n’est pas un bot automatisé pour attaquer en force brute. Ces signes clavier sont générés graphiquement (intercepter leur production et leur affichage en tant que signes ASCII est donc impossible) et la conformité de leur entrée au clavier virtuel n’est pas construite sur une équivalence de signes (A == A) mais sur les formes graphiques des signes : combien de courbes, combien de droites, combien d’angles, combien de blancs.
• Un process MFA est implémenté dans SEGMENT : l’objectif est de s’assurer que USER est bien physiquement lui en utilisant 2 devices/UA référencés (il a déclaré un « clone », voir point suivant). Sur sa machine UA-1 il entre un nombre qu’il choisit, par exemple « 12345 ». Un algorithme le factorise avec son nom réel réduit en chiffres (le même que dans ses IDs machine), le factorise avec « 12345 », hashe le résultat et lui retourne les 4 premiers + 4 derniers signes : a435f0cb. Sur une autre machine UA-2 (son phone, sa tablette, un autre PC…) il ouvre une URL SEGMENT dédiée où il devra entrer son nom User et ce hash. L’algorithme explore tous les hashs possibles jusqu’à retrouver la valeur initiale « 12345 » (donc quand substr(0,4) + substr(-4) == code), la refactorise différemment et retourne un nouveau substring de hash que User devra rentrer sur sa première machine UA-1. Son nom étant dans ses IDs, un calcul sur cette entrée + son nom User (celui de l’ID sur UA-1, vous suivez ?) devra donner exactement le même résultat.
De cette façon on est certain que :
1) User est un être physique et pas un bot,
2) qu’il connaît son nom/pseudo, et
3) qu’il détient physiquement les deux UAs, et donc que l’un des deux UAs n’a pas été perdu par son propriétaire et trouvé par quelqu’un qui cherche comment en abuser.
Les technologies MFA (Multi-Factors Authentification) sont considérées comme sûres, contrairement aux 2FA (Double-Factor) où un service en ligne – banques, plateformes – envoie un code par SMS à votre phone – qui peut être écouté – à reproduire au clavier – qui peut aussi être keysnuffé.
• Clonage d’UAs : pour des raisons de sécurisation de ses données, il est recommandé à chaque User de réaliser une « copie virtuelle » de son UA sur une autre machine (par exemple cloner son phone sur son PC). En cas de perte, de vol, de panne, de destruction, ou simplement en cas de changement d’ordinateur ou de phone, pouvoir récupérer ses datas (IDs, wallets, historiques de transactions, etc.) évite le risque qu’elles soient définitivement perdues, ou alors (en cas de vol) d’être exposé à se voir pirater son compte.
Une fois l’UA primaire cloné sur l’UA secondaire, celui-ci ne devient pas de fait un « vrai » clone : on ne peut pas l’utiliser comme machine transactante puisque ses datas ne seront pas conformes à ses caractéritiques techniques : tenter de le faire mènerait tout droit à être pris pour un hacker tentant d’usurper une identité avec destruction immédiate et irréversible des datas qu’on était supposé protéger, ce qui est un comble.
En cas de perte, vol, panne ou changement définitif d’UA, il suffit d’envoyer sur le réseau un message particulier pour qu’une transaction particulière soit créée, demandant aux « parents » de l’UA initial d’actualiser leurs blocs au profit du nouvel UA qui devient alors et de façon définitive le Node officiel de User.
Ce protocole étant par nature dangereux (imaginez un hacker prétendant être vous faisant désactiver votre appareil au profit du sien…) les process d’authentifications exposés plus haut sont doublés par d’autres contrôles non-exposés ici pour des raisons de sécurité globale.
• Un protocole KYC de type bancaire (confirmation d’identité réelle : DID « Decentralized Identity« ) peut être implémenté à la demande sur les cubes/projets le nécessitant, selon les besoins et législations en vigueur selon les pays. Contrairement aux blockchains classiques où USER est pseudonymisé, dans SEGMENT il est entièrement anonymisé : retrouver le lien entre wallets et identités réelles sans accès à cette fonction (disponible uniquement dans un cube/projet SEGMENT en version KYC) n’est pas réalisable.
→ SEGMENT est 100% conforme aux directives européennes RGPD portant sur la protection et la sécurisation des données personnelles.